With the second-term of the coding phase underway, this week I focused on the web-app development, mainly UI and integrating our parts one by one, Firstly with spotlight.
Architecture
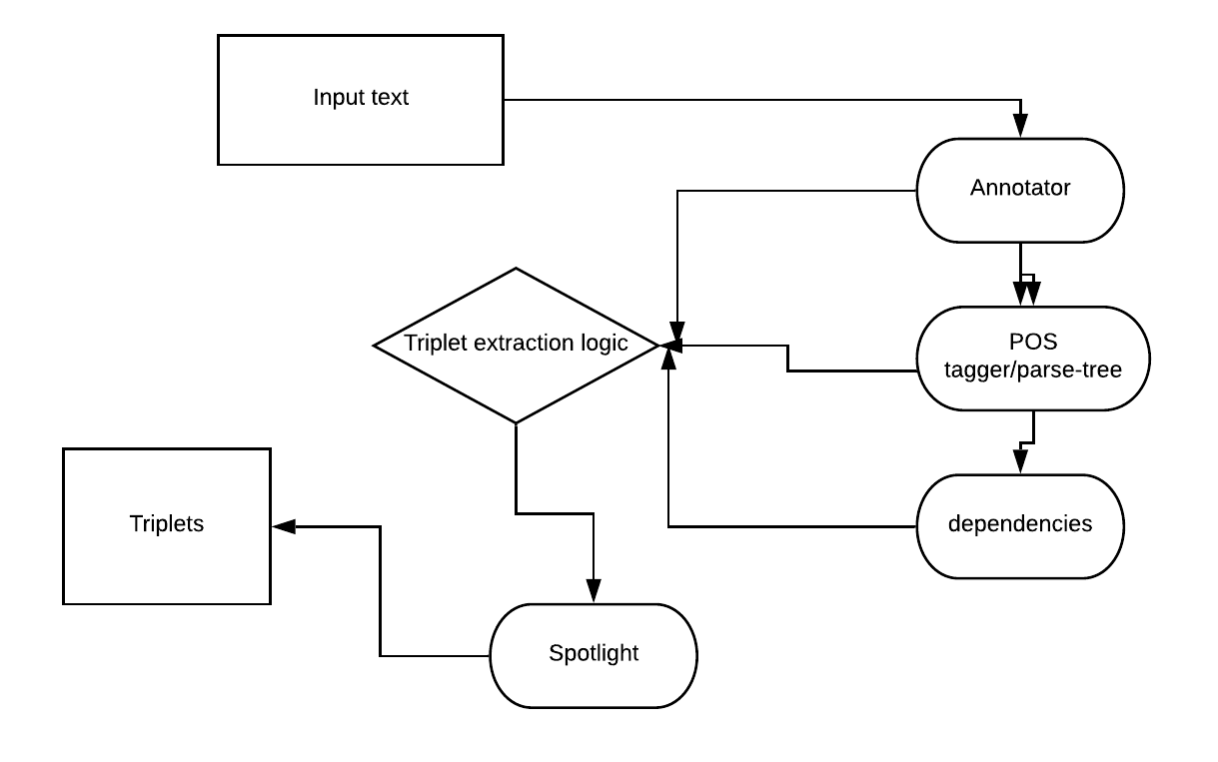
The Architecture of the web-app is straightforward:-
- The frontend-UI, which will handle inputs and outputs of the tool
- The backend which will consist of the following parts:-
- The component parts which will include
- Annotation/Entity extraction - spotlight
- POS tagging/parse-tree - stanford CORENLP/SyntaxNet or others
- dependencies - stanford CORENLP/SyntaxNet or others
- The logic which will use the above components to extract triples
- The component parts which will include
UI
The UI design for the following is pretty straight forward, which should be able to cater to features described in the previous week post
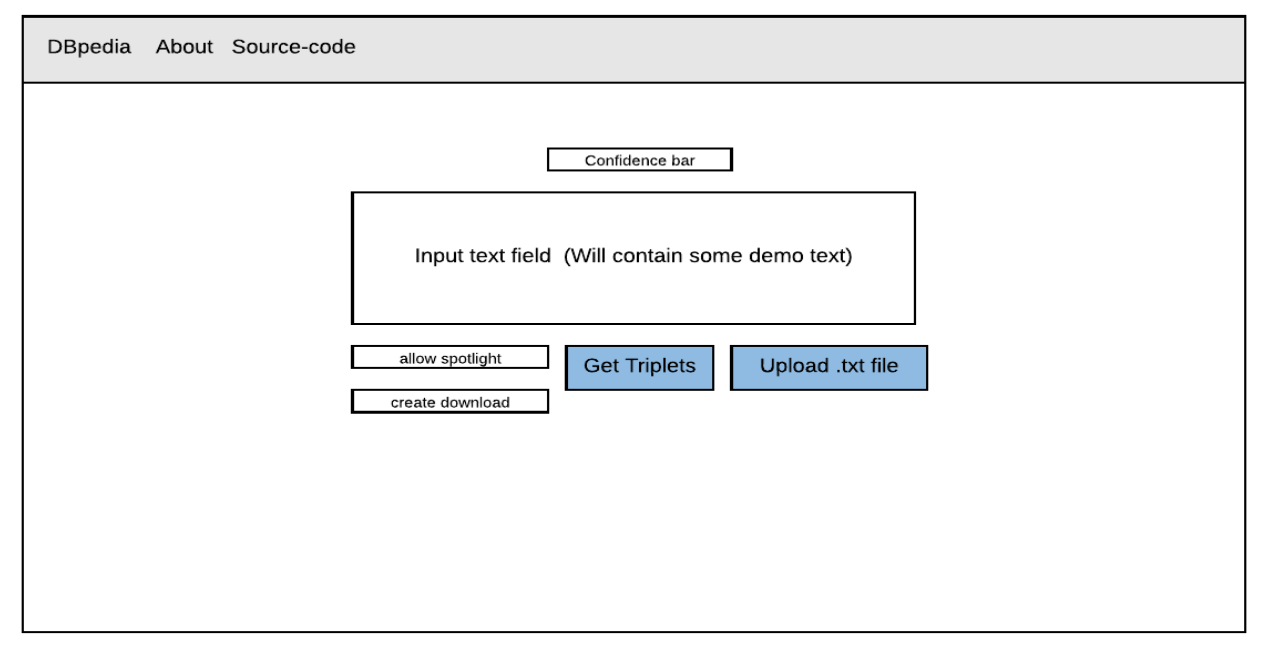
The main component however will be for the search results we display.
Integrating spotlight
Spotlight integration is the first step of our final product - entity extraction and relating that to a DBpedia source. This can be done by integrating the spotlight API into the code we are using
from .src.pyspotlight import spotlight
import nltk
spotlight_config = spotlight.Config()
spotlight_address = spotlight_config.spotlight_address
This is then added to our route search function
if q_spotlight:
annotations = spotlight.annotate(spotlight_address,
q_text)
Analysing our results however is the key to our web-app, given we extract the sentences, and also the entities. These can then be pipelined into the later components which we will be integrating in the coming weeks, in order to get the triplets.
A demo of the following app can be found at - link. Do make sure to enable the - allow spotlight feature to be able to see spotlight results.